import socketserver from Crypto.Util.number import * import os import signal import string import random from hashlib import sha256 from secret import flag
classTask(socketserver.BaseRequestHandler): def_recvall(self): BUFF_SIZE = 2048 data = b'' whileTrue: part = self.request.recv(BUFF_SIZE) data += part iflen(part) < BUFF_SIZE: break return data.strip()
defproof_of_work(self): random.seed(os.urandom(8)) proof = ''.join([random.choice(string.ascii_letters+string.digits) for _ inrange(20)]) _hexdigest = sha256(proof.encode()).hexdigest() self.send(f"sha256(XXXX+{proof[4:]}) == {_hexdigest}".encode()) x = self.recv(prompt=b'Give me XXXX: ') iflen(x) != 4or sha256(x+proof[4:].encode()).hexdigest() != _hexdigest: returnFalse returnTrue
defhandle(self): p = getPrime(512) q = getPrime(512) n = p*q e = 65537
signal.alarm(120) self.send(b'Try to factor n within 120 seconds') self.send("n = {}\ne = {}".format(n, e).encode()) self.send(b'And solve the proof-of-work below to begin the challenge.')
ifnot self.proof_of_work(): return
signal.alarm(12) secret = os.urandom(16) for i inrange(4): self.send("c{} = {}".format(i, pow(bytes_to_long(secret[4*i:4*i+4]), e, n)).encode())
self.send(b"Give me the secret:") s = self.recv() if secret.hex().encode() == s: self.send(b"Congratulations! Your flag is: "+flag.encode()) else: self.send(b"Wrong secret") self.request.close()
import os from Crypto.Util.number import * from tqdm import tqdm
count = 0 for i in tqdm(range(1000)): m = bytes_to_long(os.urandom(4)) for j inrange(2,2**16): while(m % j == 0): m //= j if(m == 1): count += 1 print(count/1000)
from Crypto.Util.number import * from pwn import * from tqdm import tqdm import string from hashlib import sha256
#context.log_level = 'debug'
defproof_of_work(): table = string.digits + string.ascii_letters r.recvuntil(b"sha256(XXXX+") temp = r.recvline() suffix = temp[:16].decode() hex1 = temp[20:].strip().decode() for i in tqdm(table): for j in table: for k in table: for m in table: temp1 = i+j+k+m if(sha256((temp1+suffix).encode()).hexdigest() == hex1): r.sendline(temp1.encode()) return
while(1): r = remote("node5.anna.nssctf.cn",28803)
#part1 r.recvline() n = int(r.recvline().strip()[3:]) e = 65537 S = {pow(i,-e,n):i for i in tqdm(range(1,2**19))} proof_of_work()
#part2 secret = "" for i inrange(4): c = int(r.recvline().split(b'=')[1].strip()) inv_c = inverse(c,n) for j inrange(1,2**16): s = inv_c*(pow(j,e,n))%n if(s in S): print(i) secret += hex(S[s]*j)[2:].zfill(8) break temp = r.recvline() r.sendline(secret.encode()) temp = r.recvline() print(temp) r.close() #flag暂时还没有,靶机有一点小问题
from Crypto.Util.number import getPrime, long_to_bytes, bytes_to_long
withopen("flag.txt", "rb") as f: FLAG = f.read()
n = bytes_to_long(FLAG)
#make sure i have a big modulus while n.bit_length() < 2048: n *= n
defencrypt(m1, m2): e = getPrime(256) assert m1.bit_length() >= 1600and long_to_bytes(m1).startswith(b"SEE{"), 'first message must be at least 1600 bits and begin with "SEE{"' assert500 <= m2.bit_length() <= 600, 'second message must be within 500 to 600 bits'
from Crypto.Util.number import * from Crypto.Cipher import AES from hashlib import md5 import random
flag = b"***********************************" defpad(message): return message + b"\x00"*((16-len(message)%16)%16)
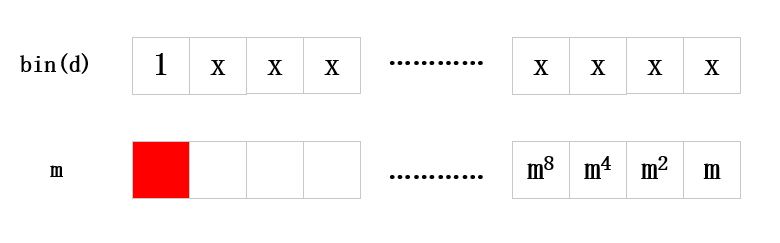
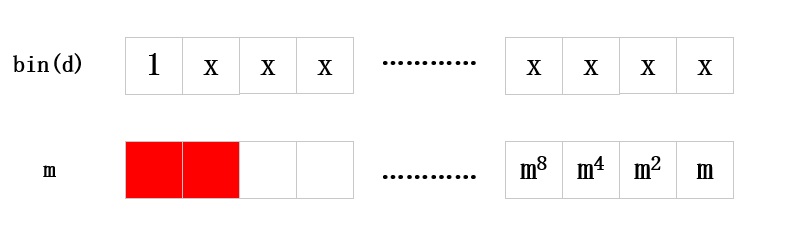
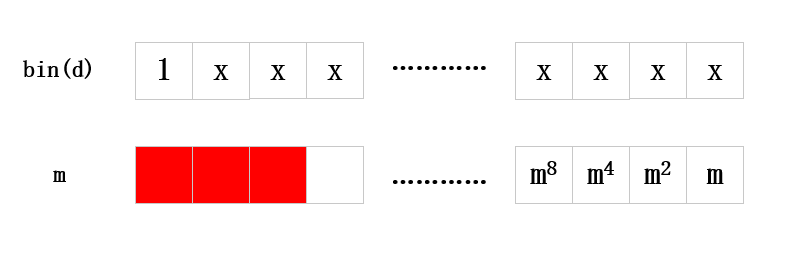
defmyfastexp(m,d,N,j,N_): A = 1 B = m d = bin(d)[2:][::-1] n = len(d) N = N for i inrange(n): if d[i] == '1': A = A * B % N # a fault occurs j steps before the end of the exponentiation if i >= n-1-j: N = N_ B = B**2 % N return A
defencrypt(message,key): key = bytes.fromhex(md5(str(key).encode()).hexdigest()) enc = AES.new(key,mode=AES.MODE_ECB) c = enc.encrypt(pad(message)) return c
border = "|" print(border*75) print(border, "Hi all, I have another algorithm that can quickly calculate powers. ", border) print(border, "But still there's something wrong with it. Your task is to get ", border) print(border, "its private key,and decrypt the cipher to cat the flag ^-^ ", border) print(border*75)
whileTrue: # generate p = getPrime(512) q = getPrime(512) n = p*q e = 17 if GCD(e,(p-1)*(q-1)) == 1: d = inverse(e,(p-1)*(q-1)) n_ = n break n_ = n msg = bytes_to_long(b"Welcome_come_to_WMCTF") sig = pow(msg,d,n) assert sig == myfastexp(msg,d,n,0,n_) CHANGE = True whileTrue: try: ans = input("| Options: \n|\t[G]et data \n|\t[S]ignatrue \n|\t[F]ault injection \n|\t[Q]uit\n").lower().strip() if ans == 'f': if CHANGE: print(border,"You have one chance to change one byte of N. ") temp,index = input("bytes, and index:").strip().split(",") assert0<= int(temp) <=255 assert0<= int(index) <= 1023 n_ = n ^ (int(temp)<<int(index)) print(border,f"[+] update: n_ -> \"{n_}\"") CHANGE = False else: print(border,"Greedy...") elif ans == 'g': print(border,f"n = {n}") print(border,f"flag_ciphertext = {encrypt(flag,d).hex()}") elif ans == 's': index = input("Where your want to interfere:").strip() sig_ = myfastexp(msg,d,n,int(index),n_) print(border,f"signature of \"Welcome_come_to_WMCTF\" is {sig_}") elif ans == 'q': quit() except Exception as e: print(border,"Err...") quit()
defmyfastexp(c,d,n): d = bin(d)[2:][::-1] m = [c] temp = c for i inrange(len(d)-1): temp = temp ** 2 % n m.append(temp) final = 1 for i inrange(len(d)): if(d[i] == "1"): final = final * m[i] % n return final
defnormal_fastexp(c,d,n): d = bin(d)[2:][::-1] final = 1 for i inrange(len(d)): if(d[i] == "1"): final = final * c % n c = c**2 % n return final
只是精简了代码,实际进行的操作依然是完全相同的。
错误注入
了解了快速幂后,再来看题目提供的错误注入代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defmyfastexp(m,d,N,j,N_): A = 1 B = m d = bin(d)[2:][::-1] n = len(d) N = N for i inrange(n): if d[i] == '1': A = A * B % N # a fault occurs j steps before the end of the exponentiation if i >= n-1-j: N = N_ B = B**2 % N return A
from Crypto.Util.number import * from pwn import * from tqdm import * from Crypto.Cipher import AES from hashlib import md5
defdecrypt(message,key): key = bytes.fromhex(md5(str(key).encode()).hexdigest()) enc = AES.new(key,mode=AES.MODE_ECB) c = enc.decrypt(message) return c
#context.log_level = 'debug' while(1): r = remote("node5.anna.nssctf.cn",28015)
#part1 get c,n r.recvuntil(b"[Q]uit") r.sendline(b"g") r.recvuntil(b"n =") n = int(r.recvline().strip().decode()) r.recvuntil(b"flag_ciphertext =") c = long_to_bytes(int(r.recvline().strip().decode(),16))
#part2 get n_ change_byte = 0 ind = 0 find = 0 for temp inrange(256): if(find): break for index inrange(1024): n_ = n ^ (temp<<index) if isPrime(n_): change_byte = temp ind = index find = 1 break
#part3 get d len_d = 1023 defgetm(m,n,n_): final = [] c = m for i inrange(len_d): final.append(c) c = c**2 % n return final msg = bytes_to_long(b"Welcome_come_to_WMCTF") m = getm(msg,n,n_)
defgetd(d,siglist,n_,m): for i in trange(1,len_d-1): current = siglist[i] inv_Bad = inverse(pow(m[len_d-1-i]**2%n_,int(d,2),n_),n_) cur = current * inv_Bad % n_ nextsig = siglist[i+1] next_inv_Bad = inverse(pow(m[len_d-2-i]**2%n_,2*int(d,2),n_),n_) inv_next = nextsig * next_inv_Bad % n_
if(inv_next == cur): d += "0" else: d += "1" return d
siglist = [] for i in trange(len_d): r.recvuntil(b"[Q]uit") r.sendline(b"s") r.recvuntil(b"interfere:") index = i r.sendline(str(index).encode()) r.recvuntil(b" is ") sig_ = int(r.recvline().strip().decode()) siglist.append(sig_)
init_d = "1" d = getd(init_d,siglist,n_,m) + "1" d = int(d,2)
import binascii import os import random import signal
defb2n(b): res = 0 for i in b: res *= 2 res += i return res
defn2b(n, length): tmp = bin(n)[2:] tmp = '0'*(length-len(tmp)) + tmp return [int(i) for i in tmp]
defs2n(s): returnint(binascii.hexlify(s), 16)
defsign(msg): msg = n2b(s2n(msg), len(msg)*8) msg += b1 for shift inrange(len(msg)-64): if msg[shift]: for i inrange(65): msg[shift+i] ^= b2[i] res = msg[-64:] return b2n(res)
if __name__ == '__main__': signal.alarm(60) withopen('/home/ctf/flag', 'r') as f: flag = f.read()
try: print("Welcome to the Signature Challenge!") raw = os.urandom(256) pos = random.randint(0, 248) raw_hex = bytearray(binascii.hexlify(raw)) for i inrange(8): raw_hex[(pos+i)*2] = ord('_') raw_hex[(pos+i)*2+1] = ord('_') raw_hex = bytes(raw_hex) print(f"Here is the message: {raw_hex.decode('ascii')}") ans = input("Please fill the blank: ") ans = bytes.fromhex(ans) assertlen(ans) == 8
raw = bytearray(raw) for i inrange(8): raw[pos+i] = ans[i] raw = bytes(raw) if sign(raw) == 0x1337733173311337: print(f"Great! Here is your flag: {flag}") else: print(f"Wrong! Bye~") except Exception: print("Error!")
from Crypto.Util.number import * from pwn import * from tqdm import *
defb2n(b): res = 0 for i in b: res *= 2 res += i return res
defn2b(n, length): tmp = bin(n)[2:] tmp = '0'*(length-len(tmp)) + tmp return [int(i) for i in tmp]
defs2n(s): returnint(binascii.hexlify(s), 16)
defsign(msg): msg = n2b(s2n(msg), len(msg)*8) msg += b1 for shift inrange(len(msg)-64): if msg[shift]: for i inrange(65): msg[shift+i] ^= b2[i] res = msg[-64:] return b2n(res)
import gmpy2 from Crypto.Util.number import * import random
from secret import flag
p = getPrime(1024) q = getPrime(1024) phi = (p-1)*(q-1) n = p*q
g = random.randint(2, n-1)
round = 10 E = 1 print(f'n = {n}') print('give you hand!') for i inrange(round): whileTrue: e = random.randint(3, 2**128) if gmpy2.gcd(e, phi) == 1: break d = gmpy2.invert(e, phi) print(e, pow(g,d,n)) E *= e print('give me fight!') C = int(input('> ').strip()) ifpow(C, E, n) == g: print('Pa!!!!') print(flag) else: print('Wrong!')
import base64 import binascii import hashlib import os import random from Crypto.PublicKey import RSA from Crypto.Util.number import bytes_to_long, long_to_bytes
from secret import message
classRSAKey: def__init__(self, e, d, n): self.e = e self.d = d self.n = n
defsend(self, ciphertext): ciphertext = base64.b64decode(ciphertext) message = self.key.decrypt(ciphertext) if message[-1:] != b'.': raise Exception('Be polite. Your message should terminate with a full-stop.') print('nice')
from Crypto.Util.number import * from gmpy2 import powmod from pwn import * from base64 import *
r = remote("archive.cryptohack.org",53580)
#part1 get n,e,c r.sendline(b"pkey") r.recvuntil(b"[pkey]") n = bytes_to_long(b64decode(r.recvline().strip().decode()))
r.sendline(b"read") r.recvuntil(b"[shhh]") c = bytes_to_long(b64decode(r.recvline().strip().decode())) e = 65537
#part2 get first_range of m x = 1 while(1): msg = powmod((256*x + 1),e,n)*c % n msg = long_to_bytes(msg) r.sendline(b"send " + b64encode(msg)) if(b"nice"in r.recvline()): x *= 2 else: break print("Part1 Done!")
#part3 get final_range of m L = x // 2 R = x while(1): if(x == (L+R) // 2): break x = (L + R) // 2 msg = powmod((256*x + 1),e,n)*c % n msg = long_to_bytes(msg) r.sendline(b"send " + b64encode(msg)) if(b"nice"in r.recvline()): L = x else: R = x
flag = n // (256*x + 1) print(long_to_bytes(flag))
whileTrue: self.send(b"| Options: \n|\t[T]ry the magic machine \n|\t[Q]uit") ans = self.recv().lower()
if ans == b't': self.send(border+b"please send your desired integer: ") g = self.recv() try: g = int(g) except: self.send(border+b"The given input is not integer!") break sleep(0.3) if ts(g, p): t, r = pow_d(g, s, p) if r == 4: self.send(border+b'Great! you got the flag:'+flag) else: self.send(border+b"t, r = "+f"{t, r}".encode()) else: self.send(border+"The given base is NOT valid!!!") elif ans == b'q': self.send(border+"Quitting ...") break else: self.send(border+"Bye bye ...") break
for i inrange(0, len(plaintext), self.block_size): block = plaintext[i:i+self.block_size] idx = 0 for _ inrange(self.rounds): L, R = block[:idx]+block[idx+1:], block[idx:idx+1] L, R = strxor(L, self.F(R)), R block = L + R idx = R[0] % self.block_size ciphertext += block
return ciphertext.hex()
key = urandom(16) cipher = Cipher(key) flag = open('flag.txt', 'rb').read().strip()
print("pilfer techies") whileTrue: choice = input("1. Encrypt a message\n2. Get encrypted flag\n3. Exit\n> ").strip() if choice == '1': pt = input("Enter your message in hex: ").strip() pt = bytes.fromhex(pt) print(cipher.encrypt(pt)) elif choice == '2': print(cipher.encrypt(flag)) else: break
defget_choice(io,payload): io.recvuntil(b'>') io.sendline(b'1') io.recvuntil(b'Enter your message in hex: ') io.sendline(payload) enc = io.recvline() return enc.strip().decode()
defattack(): start = time() for iii in tqdm("_0123456789abcdefghijklmnopqrstuvwxyz"): for jjj inrange(40): io = remote('chal.amt.rs',1415) head = get_flag_enc(io)[128:160]