*代表赛中未出题目。赛中一共做出两道,最后一道目前还没有进一步的思路,所以先阐述一下自己的想法,希望能给各位师傅一些启发。
一眼看出
题目描述:
1 | 一眼看穿 |
题目:
1 | from Crypto.Util.number import * |
签到题,没有太多可说的东西。主要就是r只有六位,因此可以爆破求出n的分解。
exp:
1 | from Crypto.Util.number import * |
almostlinear
题目描述:
1 | 我的Sbox不是线性的!原来随便调整一下就好了,那么用这样的Sbox就安全了……叭? |
题目:
task.py:
1 | # !/usr/bin/env python |
cons.py:
1 | from secret import sbox_linear |
还有一个AES的具体实现,和加密后的hint,需要全部附件的师傅可以找我要。
这个题抢到一个一血,值得纪念。回到题目,还是简单分析一下题目任务:
- 通过proof
- 随机生成16字节的AES密钥,并随机生成一个十六字节且每个字节都是十六进制数的token
- 首先给出用他的AES加密后的token
- 然后,我们可以输入一段值,并获得这段值用他的AES加密的结果
- 最后我们需要用这些信息解出token值并传回给他,token正确就能得到flag
- 有一个需要额外注意的点,就是每一次连接靶机有一千次机会可以传回token,正确一次就可以得到flag。所以解决这题应该是个概率性的问题
那么首先观察他的AES究竟做了一些什么变化,测试出来其实就是S盒改变了而已。结合题目提示,这个S盒肯定有不安全的地方。这一部分让我想到前一段时间做的羊城杯决赛的newAES一题,于是我先分析一下这个S盒的抗差分性质,然后发现果然这个S盒的抗差分性质非常差。
对于S盒的差分分析不太清楚的可以看看我写的这篇:
Crypto趣题-分组密码 | 糖醋小鸡块的blog (tangcuxiaojikuai.xyz)
但是,newAES那个题目中,他的S盒是完全差分可逆的,但是这一题的S盒只是抗差分性质较差,并不完全可逆。这里我具体列举一下差分分布表的其中一行让大家可以看出区别:
正常S盒:
1 | [0, 2, 0, 0, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 0, 2, 2, 0, 0, 2, 2, 2, 0, 0, 0, 2, 4, 0, 2, 2, 0, 2, 0, 0, 0, 0, 2, 2, 0, 0, 2, 0, 2, 2, 2, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 2, 0, 0, 0, 2, 0, 0, 0, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0, 2, 0, 2, 2, 0, 0, 0, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 2, 2, 0, 2, 0, 0, 0, 2, 2, 2, 2, 0, 2, 0, 0, 0, 2, 0, 0, 2, 0, 0, 2, 2, 0, 0, 0, 2, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 0, 2, 2, 0, 0, 0, 2, 0, 0, 2, 0, 2, 0, 0, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 2, 0, 0, 2, 0, 2, 2, 2, 2, 2, 2, 0, 0, 2, 0, 2, 0, 2, 2, 2, 2, 0, 0, 2, 0, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 0, 2, 2, 0, 0, 0, 0, 2, 0, 0, 0, 2, 2, 0, 0, 2, 2, 0, 0, 2, 0, 0, 2, 0, 0, 2, 0, 0, 2, 2, 2, 0, 0, 2, 0, 0, 0, 2, 2, 2, 0, 2, 2, 0, 0, 0, 2] |
羊城杯那题S盒的差分分布:
1 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 256, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
本题S盒的差分分布:
1 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 246, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
对于完全差分可逆的S盒(如羊城杯那题的S盒),我们拥有输入的值的密文以及token的密文,所以就有密文差分,然后由于差分可逆,就可以逐步将差分逆回去得到明文差分,然后将明文差分与我们的输入值异或,就得到了token。
而本题S盒虽然并不是完全差分可逆的,但是可以观察到,他的差分分布仍然极不均匀,一个明文差分在经历S盒后,大部分会集中在另一个差分。因此,我们可以把这个集中分布的差分视作是差分可逆的,去求解我们的密文差分。而只要我们随机到一个token,使其与我们的输入密文满足AES中所有差分均对应在这个集中分布的差分上,就可以解出token。因此解法是概率性的,具体的概率我简单想了一下,应该是这样计算:记AES中用到差分S盒的次数为n,那么成功概率应该是:
理论上来说非常低,但是既然提供了多次交互次数,那么由生日攻击的原理知道,我们交互多次就有大概率得到一组满足题意的解。
这就是我的做法,我赛中连接几十次靶机就随机到了一组满足条件的token值,进而获得flag。这个解法也并没有用到题目的hint,所以可能有其他进一步的优化方法可以提高这个概率,使其能在一次连接靶机内就随机出能解的token。(因为并没有具体计算这个概率为多大,所以也可能是运气非常好,才能在几十次内得到解)
exp:
1 | from Crypto.Util.number import * |
*doublecheck
题目描述:
1 | 我的加密机不知道为什么莫名其妙坏了,输出的密文好像总是有些问题……不过既然如此,那我就有了一个新的加密机,一起使用的话,满足同时绕过两个加密机可就难喽~ |
题目:
1 | # !/usr/bin/env python |
题目任务挺简单的,总结一下就是:
- 通过proof
- 随机生成16字节的key,并随机生成一个十六字节且每个字节都是十六进制数的pts
- 将pts分别用cipher、cipher_broken进行加密,并给出两个密文
- 传给靶机pts,如果正确则得到flag
那么核心任务就是找到两个加密文件的区别,并找出这个区别会对密文分别造成什么影响,然后用这个泄露信息去解密。
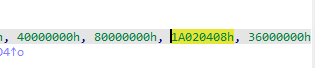
拖进IDA里看看加密过程,发现两个cipher其实都是标准AES加密,代码部分没有任何不同。那么应该也是改变了AES中的某个常量,进一步就会发现,cipher_broken的密钥扩展中的轮常量的倒数第二个值发生了变化。
正常的是:

broken的是:
那么就要通过这个区别来想办法解AES。然后我的思路如下(看不太明白的师傅可以熟悉一下AES的加密流程):
尝试
我的思路主要是利用第十轮解密以及第十轮密钥扩展来对第十轮密钥进行逐字节爆破:
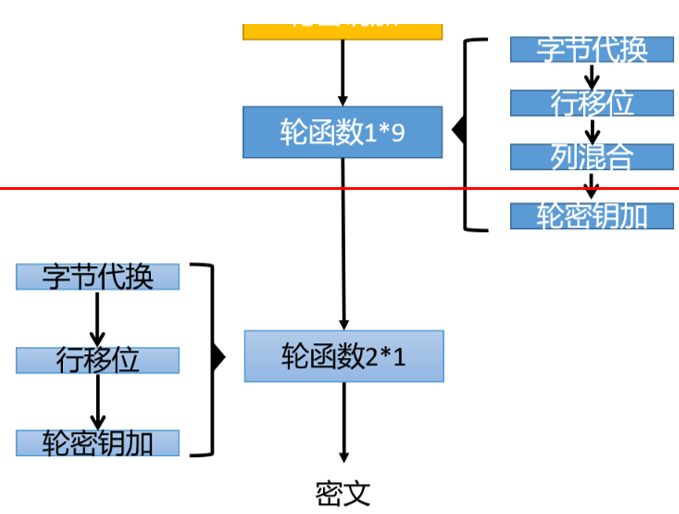
利用第十轮解密
由于第九轮轮常量有区别,因此密钥扩展算法后的第九轮和第十轮轮密钥会受到影响。换一个角度,这也就是说在进行第九轮的轮密钥加之前,两个AES加密得到的结果都是完全一样的,也就是下图中,红线部分的值对于两个AES都相同,在第九轮轮密钥加之后开始产生区别:
而由于第九轮轮常量的不同,两个AES的第九轮轮密钥会产生如下的区别(左为正常AES第九轮轮密钥,右为broken的第九轮轮密钥):
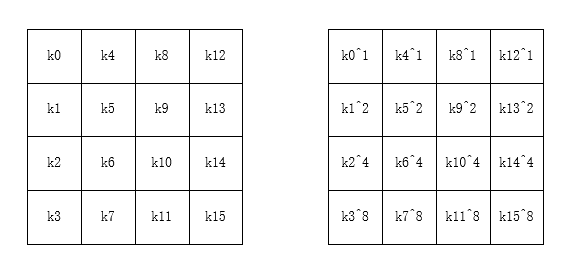
而现在我们拥有密文,我们可以用中间相遇攻击的类似思路来逐字节爆破第十轮轮密钥,然后有了完整的第十轮轮密钥的话就可以用AES子密钥泄漏来反推所有密钥,进而解得AES明文。逐字节爆破的思路如下,这里我以第一次爆破为例:
- 爆破正常第十轮轮密钥的第一个字节,和broken第十轮轮密钥的第一个字节
- 将两个密文的第一个字节经过第十轮的逆轮密钥加->逆行移位->逆字节代换后,得到两个第九轮的轮密钥加之后的值,也就是下图黄线处的值:
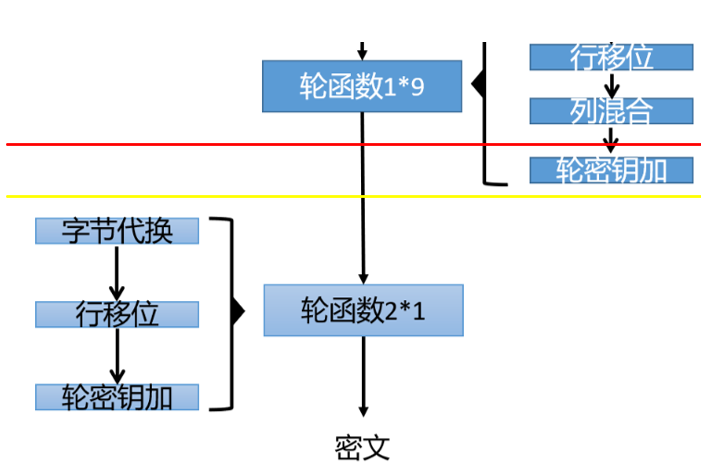
- 然后,由于两个AES的第九轮轮密钥差分是固定的,因此两个密文的差分应该也是固定的。比如对于第一个字节来说,黄线处的值差分应该等于1
- 满足上面条件的就是可能的第十轮轮密钥的第一个字节
这样爆破完后,会发现每一个密钥仍然有256种可能性(注意一次其实是爆破两个字节,所以这里将可能性由2^16降到了2^8,确实是有效果的)。这里要注意:轮密钥有多种可能性是可以接受的,因为我们可以检查解出的密文是不是每个字节均是16进制字符。但是,显然这里的可能性还是太多了。因此还要想办法再降。
利用第十轮密钥扩展
然后下一步我的做法就是利用密钥扩展算法:
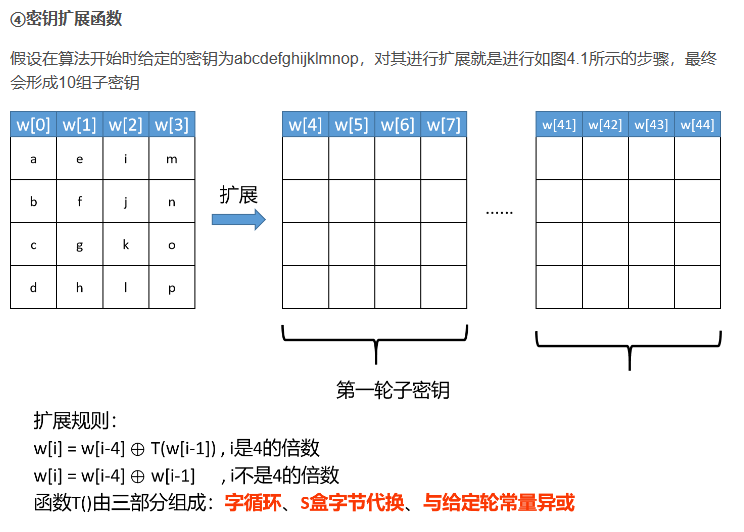
也就是,我们将上一步的第十轮轮密钥的所有可能值爆破完后,继续逐字节爆破第九轮轮密钥的每个字节,并检查密钥扩展得到的两个第十轮密钥的这个字节是否在刚才得到的所有可能性里,如果不在的话,就可以从第十轮密钥的可能值中剔除掉,并且这一步是可以反复做的。经过测试发现,这样最多五轮后就无法再降低可能性,第十轮轮密钥的每个字节降低到了六十对左右(要记得这里本来是2^16对,到这里已经降低了很多)。
但是复杂度依然是不可接受的,我们还需要进一步减少第十轮轮密钥的可能性,但是我就没有想到进一步的做法了。
爆破脚本的本地实现如下:
1 | from Crypto.Util.number import * |
然后其中的AES_F,AES_T是我从网上找的一个可以修改AES中任意常量的加密脚本,两者的区别也就只有轮密钥,所以在这里仅列出AES_T:
1 | class AES_T: |
如果对我的想法不太明白、或者觉得有些问题的师傅欢迎与我讨论!