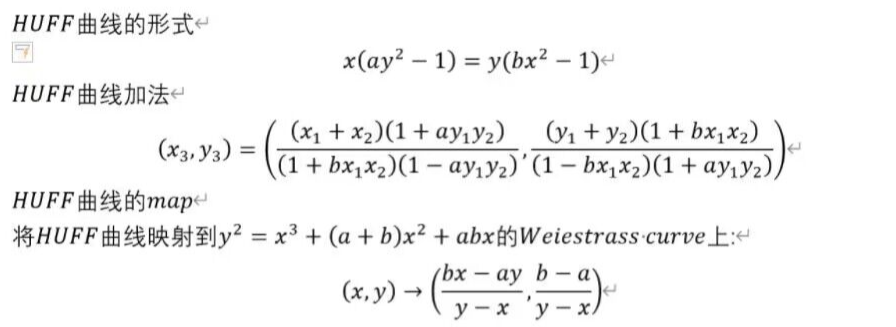defgen_e(): e = [] for i inrange(8): ee = [0]*3+[1]*3 shuffle(ee) e += ee return e e = gen_e() nbit = len(e) flag = 'DASCTF{'+sha256(''.join([str(i) for i in e]).encode()).hexdigest()+'}'
defadd(self, P, Q): if P == -1: return Q (x1, y1) = P (x2, y2) = Q x3 = (x1+x2)*(1+self.a*y1*y2)*inverse((1+self.b*x1*x2)*(1-self.a*y1*y2),self.p)% self.p y3 = (y1+y2)*(1+self.b*x1*x2)*inverse((1-self.b*x1*x2)*(1+self.a*y1*y2),self.p)% self.p return (x3, y3)
defmul(self, x, P): Q = -1 while x > 0: if x & 1: Q = self.add(Q, P) P = self.add(P, P) x = x >> 1 return Q defnegG(self,G): return self.mul(order-1,G)
ecc = CB_curve() G = (586066762126624229327260483658353973556531595840920560414263113786807168248797, 66727759687879628160487324122999265926655929132333860726404158613654375336028) P = (ecc.mul(bytes_to_long(flag),G)[0],randint(1,ecc.p)) Q = (460843895959181097343292934009653542386784127282375019764638432240505304648101, 739422832583403823403837831802136107593509589942947902014204968923412689379907)
e = randint(1,p) pl = [ecc.add(P,ecc.mul(10-i,ecc.negG(Q)))[0] + e for i inrange(10)] ph = [ecc.add(P,ecc.mul(10-i,Q))[0] + e for i inrange(10)]
defadd(self, P, Q): if P == -1: return Q (x1, y1) = P (x2, y2) = Q x3 = (x1+x2)*(1+self.a*y1*y2)*inverse((1+self.b*x1*x2)*(1-self.a*y1*y2),self.p)% self.p y3 = (y1+y2)*(1+self.b*x1*x2)*inverse((1-self.b*x1*x2)*(1+self.a*y1*y2),self.p)% self.p return (x3, y3)
defmul(self, x, P): Q = -1 while x > 0: if x & 1: Q = self.add(Q, P) P = self.add(P, P) x = x >> 1 return Q defnegG(self,G): return self.mul(order-1,G)
#get coordinate_P PR.<xp,e> = PolynomialRing(Zmod(ecc.p)) F = [] for i inrange(10): f = (pl[i]-e)*(ph[i]-e)*(1-ecc.b^2*xp^2*(ecc.mul(10-i,Q)[0]^2)) - (xp^2-(ecc.mul(10-i,Q)[0]^2)) F.append(f) res = Ideal(F).groebner_basis() #print(res) #[xp^2 + 219493165434454878473973957507132663767650700404392831423708684433961924200902, e + 716700711017198421972376297958894204723153539777056104579499803899129208364755]
xp_2 = -219493165434454878473973957507132663767650700404392831423708684433961924200902 F = Zmod(ecc.p) xp_2 = F(xp_2) xp = xp_2.nth_root(2,all=True)
points = [] PR.<yp> = PolynomialRing(Zmod(ecc.p)) for x in xp: f = x*(ecc.a*yp^2-1) - yp*(ecc.b*x^2-1) res = f.roots() points.append((int(x),int(res[0][0]))) points.append((int(x),int(res[1][0])))
#mapping and pohlig_hellman defmapping(point): x = point[0] y = point[1] Ex = (ecc.b*x-ecc.a*y) * inverse(y-x,ecc.p) % ecc.p Ey = (ecc.b-ecc.a) * inverse(y-x,ecc.p) % ecc.p return (Ex,Ey)
defpohlig_hellman(q,g,primes,order): logs=[] for fac in primes: t=int(order)//int(fac) log=discrete_log(t*q,t*g,operation='+') logs+=[log] m = crt(logs,primes) return m
# DLP E = EllipticCurve(GF(ecc.p),[0,ecc.a+ecc.b,0,ecc.a*ecc.b,0]) #print(E.order()) order = 1141741939958844590498346884870015122544171009688372185479632675211885925945760 order_factors = [3,5,37,271,4297,6983,9679,52631,139571,84666937,558977989] EG = E(mapping(G)) for point in points: try: EP = E(mapping(point)) m = pohlig_hellman(EP,EG,order_factors,order) print(long_to_bytes(m)) except: pass
defiv(): a,b,c = L1.next(),L2.next(),L3.next() return (a & b) ^ (b & c) ^ c
classCB_cipher(): def__init__(self): key = [''.join([str(randint(0,1)) for i inrange(16)]) for j inrange(2)]
self.key = [[int(j) for j in i] for i in key] self.sbox = [0x6, 0x4, 0xc, 0x5, 0x0, 0x7, 0x2, 0xe, 0x1, 0xf, 0x3, 0xd, 0x8, 0xa, 0x9, 0xb] defs_trans(self,pt): pt = ''.join([str(i) for i in pt]) pt = [self.sbox[int(i,16)] for i inhex(int(pt,2))[2:].rjust(4,'0')] ct = ''.join([bin(i)[2:].rjust(4,'0') for i in pt]) ct = [int(i) for i in ct] return ct defencrypt(self,pltxt): key_add = lambda x,key : [x[i]^key[i] for i inrange(len(x))] bit_move = lambda x : [x[(i//4)+(i%4)*4] for i inrange(len(x))] ct = [int(i) for i in pltxt] for i inrange(5): ct = key_add(ct,self.key[i%2]) ct = self.s_trans(ct) if (i+1)%2: ct = bit_move(ct) ct = key_add(ct,self.key[1]) return''.join([str(i) for i in ct]) defbt_to_bin(self,msg): msg = msg if (len(msg)+1)%2else msg+b'\x00' returnbin(bytes_to_long(msg))[2:].rjust(8*len(msg),'0') deftxt_encrypt(self,msg): time = (len(msg)+1)//2 pltxt = [self.bt_to_bin(msg)[i*16:i*16+16] for i inrange(time)] #print(pltxt) output = [] for i inrange(time): now_re = self.encrypt(pltxt[i]) if output != []: now_re = bin(int(now_re,2) ^ int(output[-1],2))[2:].rjust(16,'0') output.append(now_re) return long_to_bytes(int(''.join(output),2)) L1 = LFSR(fpoly = fpoly1, initstate = state1) L2 = LFSR(fpoly = fpoly2, initstate = state2) L3 = LFSR(fpoly = fpoly3, initstate = state3)
iv_txt = '' for i inrange(len(flag)*8): iv_txt += str(iv()) a = CB_cipher()
print(iv_txt[:320]) print(a.txt_encrypt(b'Welcome to our CBCTF! I hope you can have a nice day here. Come with me.')) print(long_to_bytes(bytes_to_long(a.txt_encrypt(flag))^int(iv_txt,2)))
c = "10101010100110100000111111011110111101010010011000011011001010010010111000100101011111010001110110110111000010100001010111110110000011110100110011011110001100100011101101110001000100111100001111100111010100010000001101001001000011110001100110101100101000101001110011101100001100100000011101011110100110110110000110010101"
c1 = b'\x10\x07t9\x88\x95\x8b&\xb2\x8fp\xe7\xce\\k{\xbb\xe5\xa7\xb8\x92\xbe\xd1\n\x84.\xe1\xe0\xab\x08\x97\x92\x1a\xbd\xdf\x80R\xbe\xe2\x84\xe17\x14\x8a\x07\x03\x87)\xb2\xa6W:\xda\x04Y\xa5\xca\x16o1\x93\x9d\x90.\xcdS\xd6\xcbK\xf4\xd8G' plain = b'Welcome to our CBCTF! I hope you can have a nice day here. Come with me.'
final_c1 = b"\x10\x07" for i inrange(2,len(c1),2): tt1 = bytes_to_long(c1[i:i+2]) tt2 = bytes_to_long(c1[i-2:i]) final_c1 += long_to_bytes(tt1^tt2,2)
defencrypt(self,pltxt): key_add = lambda x,key : [x[i]^key[i] for i inrange(len(x))] bit_move = lambda x : [x[(i//4)+(i%4)*4] for i inrange(len(x))] ct = [int(i) for i in pltxt] for i inrange(5): ct = key_add(ct,self.key[i%2]) ct = self.s_trans(ct) if (i+1)%2: ct = bit_move(ct) ct = key_add(ct,self.key[1]) return''.join([str(i) for i in ct])
其中,s_trans函数如下:
1 2 3 4 5 6
defs_trans(self,pt): pt = ''.join([str(i) for i in pt]) pt = [self.sbox[int(i,16)] for i inhex(int(pt,2))[2:].rjust(4,'0')] ct = ''.join([bin(i)[2:].rjust(4,'0') for i in pt]) ct = [int(i) for i in ct] return ct
from Crypto.Util.number import * from z3 import * from tqdm import *
c = "10101010100110100000111111011110111101010010011000011011001010010010111000100101011111010001110110110111000010100001010111110110000011110100110011011110001100100011101101110001000100111100001111100111010100010000001101001001000011110001100110101100101000101001110011101100001100100000011101011110100110110110000110010101"
#part3 get_cipher c1 = b'\x10\x07t9\x88\x95\x8b&\xb2\x8fp\xe7\xce\\k{\xbb\xe5\xa7\xb8\x92\xbe\xd1\n\x84.\xe1\xe0\xab\x08\x97\x92\x1a\xbd\xdf\x80R\xbe\xe2\x84\xe17\x14\x8a\x07\x03\x87)\xb2\xa6W:\xda\x04Y\xa5\xca\x16o1\x93\x9d\x90.\xcdS\xd6\xcbK\xf4\xd8G' plain = b'Welcome to our CBCTF! I hope you can have a nice day here. Come with me.' final_c1 = b"\x10\x07" for i inrange(2,len(c1),2): tt1 = bytes_to_long(c1[i:i+2]) tt2 = bytes_to_long(c1[i-2:i]) final_c1 += long_to_bytes(tt1^tt2,2)
#part4 Meet-in-the-Middle attack classCB_cipher(): def__init__(self): self.sbox = [0x6, 0x4, 0xc, 0x5, 0x0, 0x7, 0x2, 0xe, 0x1, 0xf, 0x3, 0xd, 0x8, 0xa, 0x9, 0xb] self.inv_sbox = [0x4, 0x8, 0x6, 0xa, 0x1, 0x3, 0x0, 0x5, 0xc, 0xe, 0xd, 0xf, 0x2, 0xb, 0x7, 0x9] defs_trans(self,pt): pt = ''.join([str(i) for i in pt]) pt = [self.sbox[int(i,16)] for i inhex(int(pt,2))[2:].rjust(4,'0')] ct = ''.join([bin(i)[2:].rjust(4,'0') for i in pt]) ct = [int(i) for i in ct] return ct definv_s_trans(self,pt): pt = ''.join([str(i) for i in pt]) pt = [self.inv_sbox[int(i,16)] for i inhex(int(pt,2))[2:].rjust(4,'0')] ct = ''.join([bin(i)[2:].rjust(4,'0') for i in pt]) ct = [int(i) for i in ct] return ct defe1(self,pltxt,k0,k1_4): key_add = lambda x,key : [x[i]^key[i] for i inrange(len(x))] bit_move = lambda x : [x[(i//4)+(i%4)*4] for i inrange(len(x))] ct = [int(i) for i in pltxt] ct = key_add(ct,k0) ct = self.s_trans(ct) ct = bit_move(ct) ct = key_add(ct[:4],k1_4) ct = self.sbox[int(''.join([str(i) for i in ct]),2)] ct = key_add([int(i) for i inbin(ct)[2:].rjust(4,'0')],k0[:4]) ct = self.sbox[int(''.join([str(i) for i in ct]),2)] ct = ct>>3 return ct defd1(self,pltxt,k1,k0_4): #print(self) key_add = lambda x,key : [x[i]^key[i] for i inrange(len(x))] bit_move = lambda x : [x[(i//4)+(i%4)*4] for i inrange(len(x))] ct = [int(i) for i in pltxt] ct = key_add(ct,k1) ct = bit_move(ct) ct = self.inv_s_trans(ct) ct = key_add(ct[:4],k0_4) ct = self.inv_sbox[int(''.join([str(i) for i in ct]),2)] ct = key_add([int(i) for i inbin(ct)[2:].rjust(4,'0')],k1[:4]) return ct[0] defbt_to_bin(self,msg): msg = msg if (len(msg)+1)%2else msg+b'\x00' returnbin(bytes_to_long(msg))[2:].rjust(8*len(msg),'0') defdecrypt(self,pltxt,key): key_add = lambda x,key : [x[i]^key[i] for i inrange(len(x))] bit_move = lambda x : [x[(i//4)+(i%4)*4] for i inrange(len(x))] ct = [int(i) for i in pltxt] #print(ct,key) ct = key_add(ct,key[1]) for i inrange(5): if (i+1)%2: ct = bit_move(ct) ct = self.inv_s_trans(ct) ct = key_add(ct,key[i%2]) return''.join([str(i) for i in ct]) deftxt_decrypt(self,msg,key): output = [] for i inrange(len(msg)): now_re = self.decrypt(msg[i],key) output.append(now_re) return long_to_bytes(int(''.join(output),2))
m1 = [bin(bytes_to_long(plain[2*i:2*i+2]))[2:].rjust(16,'0') for i inrange(36)] c1 = [bin(bytes_to_long(final_c1[2*i:2*i+2]))[2:].rjust(16,'0') for i inrange(36)] c2 = [bin(bytes_to_long(final_c2[2*i:2*i+2]))[2:].rjust(16,'0') for i inrange(49)] a = CB_cipher()
for i in trange(2**8): dic_encbit = {} k0_4 = [int(k) for k inbin(i&0xffff0000)[2:].rjust(4,'0')] k1_4 = [int(k) for k inbin(i&0x0000ffff)[2:].rjust(4,'0')] for j inrange(2**12): k0_12 = [int(k) for k inbin(j)[2:].rjust(12,'0')] k0 = k0_4+k0_12 enc = '' for i inrange(36): enc += str(a.e1(m1[i],k0,k1_4)) enc = int(enc,2) if(enc in dic_encbit.keys()): dic_encbit[enc].append(k0) else: dic_encbit[enc] = [k0] for j inrange(2**12): k1_12 = [int(k) for k inbin(j)[2:].rjust(12,'0')] k1 = k1_4+k1_12 dec = '' for i inrange(36): dec += str(a.d1(c1[i],k1,k0_4)) dec = int(dec,2) if(dec in dic_encbit.keys()): for k0 in dic_encbit[dec]: message = a.txt_decrypt(c2,[k0,k1]) if(b"DASCTF"in message): print(message) exit()
解得:
1
b'n\xa3 you break the cipher!!how could it be??????? the flag is:DASCTF{God_on_syM@etric_cRypto9raPhy}\x00'