比赛记录
Week 1
题目很基础,这里就不讲了。
Week 2
挑一道题说一说。
partial decrypt
题目描述:
1 | 解密, 但是只解密一半 |
题目:
1 | from secret import flag |
之所以想说一下这个题,是因为可能不少cryptoer随便试了试,发现h*q+m2就能得出答案,却不明白这是否是一个巧合。
这里先说结论,无论明文m长度多大,只要他小于n,这个求解方法都是完全可行的,原理如下。
首先由题目可以看出,m1,m2其实就是:
我们先把此处的模等式展开,写成等式形式:
然后,由题目知道,h满足:
不妨把刚才得到的等式代入上式:
即:
展开就能消去q^-1*q,得到:
又因为在模p意义下,所以:
而这两者仅仅是模p下相等吗?事实上他们完全相等,这是因为:(//代表整除)
也就是说k2<p,因此k2模p等于没模,所以k2 = h。
因此就有:
所以上式一定成立,因此就能恢复明文。
exp:
1 | from Crypto.Util.number import * |
Week 3
Rabin’s RSA
题目描述:
1 | Michael O. Rabin的加密方案 |
题目:
1 | from Crypto.Util.number import * |
首先观察到n较小,因此可以直接factordb分解出p、q。然后就是普通Rabin加密,原理不详述了。
exp:
1 | from Crypto.Util.number import * |
小明的密码题
题目描述:
1 | 小明正在完成课后作业, 但是屏幕的某一块地方被墨水涂黑了(我们不妨假设小明无法擦去墨水, 并且该电脑是一个真空中的球形电脑) |
题目:
1 | from Crypto.Util.number import * |
已知m高位攻击,构造的多项式如下:
x为未知的m低位小根,smallroots求解该多项式即可。
exp:
1 | from Crypto.Util.number import * |
babyrandom
题目描述:
1 | 一个简易的LCG随机数生成器 |
题目:
1 | #!/usr/bin/python3 |
其实就是一个未知a、b的LCG,只是换成了交互题。先发送1设置种子为flag,再发送2申请三组未知数即可还原参数a、b,进而得到种子flag。
exp:
1 | from Crypto.Util.number import * |
knapsack
题目描述:
1 | 来自ASIS Quals 的背包密码题 |
题目:
1 | import random |
作为ctf wiki讲解背包加密的例题,其经典性无需多言:
背包加密 - CTF Wiki (ctf-wiki.org)
exp:
1 | from Crypto.Util.number import * |
Door
题目描述:
1 | 你被锁在了自然哲学学院里面, 想办法逃出来吧 |
题目:
1 | from secret import flag |
CBC模式的预言填充攻击,这是我从Xenny师傅的密码工坊里学到的我觉得很有意思的一种攻击方式,所以在这里展开说一说。
首先看看靶机能够提供什么样的功能,首先,在与靶机连接后,靶机生成一个16字节的随机串作为AES的密钥key,然后可以:
- 选择1,可以输入两段十六进制串,分别是token和auth_code。靶机将会把token作为AES中CBC模式的iv向量,将auth_code作为密文进行解密。
- 在成功解密之后,靶机将尝试对密文进行解填充,如果解填充失败,将会输出”oops, something wrong”
- 如果解填充成功,靶机将会对解密得到的明文进行核验,核验要求:1、明文为”SoNP#”+4个数字的字符串的形式;2、四个数字需要是valid_code中的其中之一。
- 通过核验,则得到flag;通不过核验,则输出”get out”
那么分几个部分讲一下如何进行这个攻击。
解填充
很重要的一点是,解密出来的明文通不过核验,和解填充失败,靶机输出的信息分别是”get out”和”oops, something wrong”,这个区别是很重要的。那么到底针对一个明文是如何解填充的呢?查看unpad源码可以知道,pad和unpad函数默认使用的是PKCS7的填充模式。
在这个模式下,如果最后一组明文长度为15,就需要填充一字节的b”\x01”;如果为14,就需要填充两字节的b”\x02”,以此类推。需要注意的是,当明文恰好为16的整数倍时,仍然需要填充16字节的b”\x10”,这是为了在解密时能正确地识别填充字节。
可以发现,以这种方式填充,填充后的明文会有一个很重要的特性:
- 填充后的明文的最后一字节等于填充的字节的长度
因此,明文只要满足上述特性,就能正确解填充。
预言填充攻击
那么如何利用解填充的这个特性进行CBC模式下的预言填充攻击呢?我们先画一个只有一个分组的CBC模式解密图示:
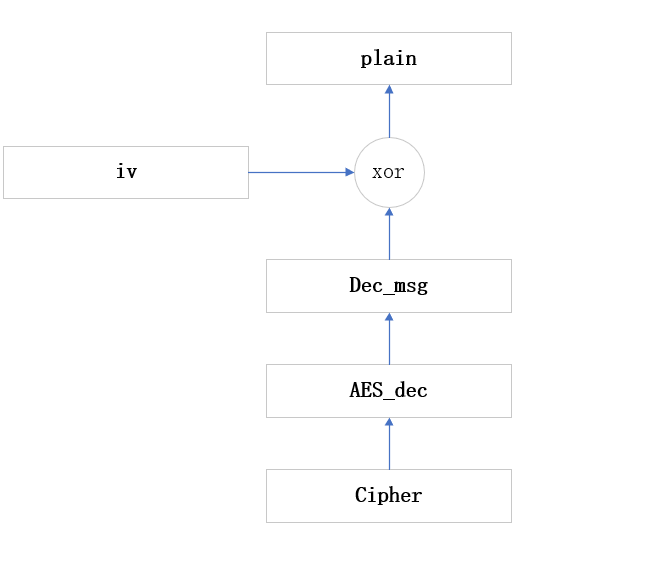
其中,cipher是我们输入的auth_code,iv是我们输入的token。cipher经AES解密后,得到dec_msg,并与iv异或后得到plain,也就是题目中的msg。
由于密钥key随机且未知,因此我们不管输入什么auth_code,我们都没有办法获得dec_msg的具体值。然而,dec_msg需要和iv异或,而iv是我们自行输入的。因此我们完全可以固定cipher,调整iv,来改变最终解密得到的plain。
那么我们假设某一次输入的cipher,iv,解密后得到的恰好是下面这样的plain:
1 | b"justatest\x07\x07\x07\x07\x07\x07\x07" |
可以看到,他满足PKCS7的填充模式,因此unpad是可以正确解密的。而我们可以调整iv的最后一字节,从而对应改变plain的最后一字节,这样他就无法正确解填充了。
然而,在某一个特殊的iv下,他仍然能正确解密,这也是我们进行攻击的根本依据。想一想在什么时候他仍然会正确解填充?
其实就是当我们输入的iv使得明文变成下面这样时:
1 | b"justatest\x07\x07\x07\x07\x07\x07\x01" |
这也是满足PKCS7填充模式的吧!所以当iv使得plain变成上面这种形式时,靶机会返回”get out”,而不是”oops, something wrong”。而这为我们也带来了一个很重要的信息,也就是dec_msg的最后一字节的值,就等于当前iv的最后一字节异或b”\x01”的值。
在这之后呢,我们将iv的最后一字节对应修改一下,使得其解密得到的plain最后一字节变成b”\x02”,接下来就如法炮制,爆破iv的倒数第二个字节,使得明文为:
1 | b"justatest\x07\x07\x07\x07\x07\x02\x02" |
此时也可以正确解填充,对应的,dec_msg的倒数第二个字节值就为当前iv的倒数第二个字节异或b”\x02”的值。
那么接下来就是对剩下十四个字节按这个方式逐个爆破,就能获得完整的dec_msg,而此时我们取token为dec_msg异或需要的msg值,就可以解密出我们需要的明文值,从而得到flag了。
exp:
1 | from Crypto.Util.number import * |
eazy_crt
题目:
1 | from Crypto.Util.number import * |
题目改编自广东强网杯2021的easycrt,并且这一题给出了S,更加简单。具体题解见我的另一篇博客:
Crypto趣题-RSA | 糖醋小鸡块的blog (tangcuxiaojikuai.xyz)
exp:
1 | from Crypto.Util.number import * |
Week 4
第四周题目其实我觉得比第三周更容易一点。
RSA Variation II
题目描述:
1 | "Schmidt Samoa" |
题目:
1 | from secret import flag |
题目已经告知是Schmidt Samoa加密方式,其加密流程类似RSA却又有不同,具体如下:
其加密为:
解密为:
之所以可以正确解密是因为:
而现在我们有N和d,则由解密流程知道,对于任意x,有:
因此有:
然后我们就能得到pq,就可以用他的解密方法解密得到明文了。
exp:
1 | from Crypto.Util.number import * |
babyNTRU
题目描述:
1 | NTRU, 但是只有常数项 |
题目:
1 | from secret import flag |
格入门时肯定会见过的一个题目,这里不做阐述了。
exp:
1 | from Crypto.Util.number import * |
Smart
题目描述:
1 | 一个解决ECDLP的好方法 |
题目:
1 | from Crypto.Util.number import * |
题目标题明示Smart attack,那么也不需要检查曲线阶是否等于p了,直接Smart attack就好。
exp:
1 | from Crypto.Util.number import * |
signin
题目描述:
1 | 签个道吧 |
题目:
1 | from Crypto.Util.number import isPrime,bytes_to_long, sieve_base |
可以发现素数的生成方式均满足p-1光滑,因此可以求出p、q。然后发现:
那么预期应该是先求出3的逆元,然后高次Rabin解。不过最近才新学了一招nth_root,试验一下发现真行,这函数很舒服。
exp:
1 | from Crypto.Util.number import * |
error
题目描述:
1 | 从错误中学习 |
题目:
1 | from sage.all import * |
题目描述与标题都说明这是一个LWE(Learning With Errors)问题,不过这道题目自己造格也很容易,这里还是先梳理一下题目加密流程。
- 将flag每个字符的ASCII码存储到列表data中,并将data分为长度相等的三段,分别作为向量x、y、z
- 生成三个随机矩阵A、B、C,其大小均为mod*n,其中元素为(-q/2,q/2)之间的随机数
- 生成一个误差向量e,其元素为(-4,1)的随机数
- 计算向量b,满足:
1 | b = x*B+y*A+z*C + e |
- 给出A、B、C、b,要求还原flag
由于flag的ASCII码被存在列表data中,而data又被分为三段向量x、y、z,因此本题其实就是要还原x、y、z向量。而我们拥有的等量关系是:
1 | b = x*B+y*A+z*C + e |
把他展开写为直观形式:
其实也就是下面的形式:
稍微移项变形一下:
而由于误差e是个很短的向量,那么以此关系就能构造一个格:
LLL就能规约得到向量e,然后解下面这个矩阵方程就能得到x、y、z,就能还原flag了:
实际上手操作时,由于sage矩阵的输出形式有点不尽人意,没办法直接读取,所以需要做一点处理。我的处理方式是:
- 新建一个空白matrix.txt文件
- 把enc.out的所有内容粘贴到matrix.txt文件中
- 将” “(四个空格)全局替换为”,”,再将” “(三个空格)全局替换为”,”,再将” “(两个空格)全局替换为”,”,再将” “(一个空格)全局替换为”,”
- 将”[,”全局替换为”[“,并在每个矩阵开头多加一个”[“,在每个矩阵结尾多加一个”]”
- 将”A=”、”B=”、”C=”、”b=”全部替换为”=”,主要是为了分隔几个矩阵
- 再进行一些可能进行的微调
然后就可以以如下方式读入矩阵和向量:
1 | with open('matrix.txt','r') as f: |
其实用正则表达式来寻找每一行的所有数字应该会更方便,但是我不太会操作。
exp:
1 | from Crypto.Util.number import * |
Week 5
last_signin
题目描述:
1 | coppersmith可以帮助你 |
题目:
1 | from Crypto.Util.number import * |
这题前段时间也有个师傅问过我,其实是D3CTF的一道原题,wp如下:
D^3CTF 官方Write Up-安全客 - 安全资讯平台 (anquanke.com)
用wp中的exp可以进行这道题目的二元copper求解,而用普通的二元copper的话,不管是调参还是多爆破几位也出不来结果,具体原因就没研究过了。
exp:
1 | from Crypto.Util.number import * |
School of CRC32
题目描述:
1 | 来点CRC32挑战 |
题目:
1 | import secrets |
题目要求进行一百轮挑战,全部通过就有flag,挑战的具体内容是:
- 生成32bit的随机数target,作为CRC32的目标值
- 输入一段长度为20的字节流,使得该字节流的CRC32值与给定target相等
当然可以去根据CRC的仿射与差分的相关性质去建立矩阵,然后求解矩阵方程得到碰撞。但是实际上知道有个轮子的话就很简单了:
exp:
1 | import crcsolver |
PseudoHell_EASY/PseudoHell_HARD
两个题其实共用一个附件,因此也放在一起说了
题目描述:
1 | 欢迎来到随机天堂,来猜猜我投的硬币是1还是0吧 |
题目:
problems.py:
1 | from challenge import Challenge1,Challenge2,Challenge3,Challenge4,Challenge5 |
challenge.py:
1 | import os |
题目代码挺长的,先简要地描述一下主要任务:
- 题目连续生成五个猜硬币挑战,通过一个挑战才能进行下一个挑战
- 对于每个挑战,需要猜测成功33次硬币即可通过挑战
- 猜测硬币的依据是:靶机提供输入功能可以输入一段字节流,而对于硬币为0或为1,会有不同的随机数产生方式,对输入的字节流产生随机数并返回。
- 对于每个挑战中的每一次猜硬币,可以指定输入次数,这个次数是五次挑战共享的,也就是说,如果前面用的次数多,后面能用的次数就少;前面用的少,后面能用的次数就很充裕。
- 对于指定的challenge,可以使用inverse功能,获取某个输入的解密结果
那么核心任务就是:
- 判断出每个challenge中,硬币为0或1时产生的随机数有什么不同,从而构造对应的输入,用得到的对应输出的特点去判断
- 对每一次挑战,尽可能用更少的输入次数,从而使后面的次数更加充裕
然后,对于5个challenge,其随机数产生都是基于两个类的:
1 | class PRP(): |
这两个类分别指的是伪随机置换(PRP)和伪随机函数(PRF),其具体区别可以参考:
那么接下来就逐个挑战分析:
challenge 1
1 | class Challenge1: |
可以看到,对于硬币为0或为1,其对输入的串的处理方式不同:
- 为0,把输入串分为左右两部分,然后如下得到结果
1 | L, R = R, xor(L, self.RO1.tran(R)) |
- 为1,直接输出一个长度为16的随机字节流
那么如何区分也很显然。我们请求一次输入次数,然后输入长度为16的全0字节,然后若靶机返回的输出前8个字节为全0,说明硬币为0;否则为1。
challenge 2
1 | class Challenge2: |
与challenge1的区别在于,硬币为0时,这个类feistel结构多进行了一轮,因此无法直接从输出进行判断。
但是解决方式也很容易,我们请求两次输入次数:
如果硬币是0:
- 第一次,输入长度为16的全0字节流,得到对应输出,推导一下可以知道输出的左右两部分是如下形式:
- 第二次,我们输入:
- 可以简单推导一下,我们得到的输出应该是:
而如果硬币是1,显然输出不会是这个结构,因此我们就可以通过挑战二。
challenge 3
1 | class Challenge3: |
相比起challenge2,又多加了一轮feistel,不过不同的是,我们可以通过inverse进行解密。
那就很简单了,我们请求两次输入次数,第一次随便输入一个字节流并获得其加密结果,第二轮输入得到的加密结果,并看inverse的结果与第一轮是否相等就好了。相等为0,否则为1。
challenge 4
1 | class Challenge4: |
挑战4中,如果硬币为0,则会将输入分为左右两部分,并反复进行tran和异或操作。不过可以看出,如果我们将输入的右半部分取为全0,异或操作相当于没有进行,而只有两轮tran。
那么同样,我们请求两次输入,第一次输入长度为16的全0字节流得到加密结果,然后第二次将加密结果再连接上8字节的0去inverse,解密得到全0说明硬币为0,否则为1。
challenge 5
1 | class Challenge5: |
这题与前面的4个challenge有两个明显区别:
- 加密的明文仅有1字节
- 既有PRP又有PRF
那么肯定就是要利用两者的区别。而最明显的区别就在于,PRP会建立一个双射,从而保证能进行逆操作,但是PRF不会。
什么意思呢?比如我们输入1和2,PRP能保证输入的两个自变量对应的函数值不同,但是PRF不保证,也就是说输入1,2,返回值可能均为1。
而我们前面共请求了1+2+2+2次,还可以用48次。因此可以请求48次输入次数,并用靶机返回的值建立字典并检查字典长度。如果长度为48则硬币大概率为0,否则为1。
注意我这里说的是大概率为0,概率具体有多大呢?我们其实可以把他看做一个等价的事件,也就是:
- 从0-255中随机抽取48次,48次全部都不一样。
这个时候我们的判断就会失败,因为此时PRF和PRP字典长度均为48。而这个失败的概率为:
而经计算,这个概率大约为:
1 | t = 0.009029416209217144 |
可以看到对于每一次,我们只有不到1%的非常小的概率失败,而我们同样也可以计算33次全部成功的概率如下:
计算得到:
1 | 0.7413190801200953 |
所以我们有很大概率成功,这也是生日攻击的理论基础。
完整exp如下:
1 | from pwn import * |